




Modern enterprises increasingly rely on deep learning to power mission-critical workflows such as global demand forecasting, inventory optimization, supply chain prediction, video-based defect detection, and financial risk modeling. These workloads demonstrate rapidly increasing GPU requirements, growing dataset volumes, and tighter governance expectations. Cloud compute alone often becomes cost-prohibitive, while on-premises compute alone restricts agility and collaboration. As a result, hybrid deep learning architectures, combining cloud-scale data engineering with on-premises GPU acceleration, are moving from experimental patterns to enterprise standards.
This article presents a production-validated hybrid architecture and the practical implementation approach behind it. The system integrates:
- Azure Databricks for scalable ETL, feature engineering, data pipelining, and MLflow tracking
- Azure Data Lake Storage (ABFS) as a unified data backbone shared across cloud and on-premises environments
- NVIDIA DGX A100 servers for deterministic, high-performance GPU training
- Azure DevOps as the orchestration and automation layer coordinating ETL, training, and post-processing
- Azure ARC for governance, identity, policy enforcement, and compliance across hybrid infrastructure
- Blobfuse2, Hadoop-Azure, Managed Identity authentication, and extended ARC integrations for secure data access
The solution was originally developed for a large-scale Demand Forecasting and Deep Learning initiative, but the design now serves as a reusable blueprint for other teams across the enterprise.
This document describes the rationale behind the hybrid decision, how the platform was designed, built, and adopted, from the initial problem framing to a fully operational hybrid ML lifecycle.
Why hybrid deep learning matters
Enterprises that adopt deep learning quickly confront a key tension:
- Cloud GPUs offer rapid scale but unpredictable and often high costs;
- On-premises GPUs provide predictable performance but lack cloud-scale ETL and orchestration flexibility;
- Compliance and data residency requirements further restrict data movement; and
- Reproducibility must span both cloud and on-prem environments.
The organization’s model training workloads, based on multi-year historical data, time-series transformations, and millions of SKUs demanded significant GPU capacity. Early iterations relied exclusively on cloud A100 VMs, but despite tuning and scheduling optimizations, costs became difficult to control. Due to unpredictable data refresh cycles and model re-training frequencies, GPU consumption fluctuated week to week, leading to volatile and increasingly unsustainable cloud spend. At the same time, the company possessed powerful on-premises NVIDIA DGX A100 servers capable of handling these workloads with stable performance and zero incremental cost per run. However, without secure connectivity and identity integration, DGX was isolated, available, but unusable within the cloud-first ML pipeline.
The organization had invested in Microsoft Azure, including Data Lake for centralized storage, Databricks for ETL and ML development, Azure DevOps for automation, and Azure Key Vault for secret management. To deliver forecasting models in production, the teams needed the best of both worlds: cloud-scale ETL, on-prem GPU-efficient training, unified governance, fully automated pipelines, secure and compliant architecture, and fast iteration cycles. This became the starting point for the hybrid deep learning platform, designed to integrate on-prem GPU power into a secure, automated, and reproducible cloud-based ML workflow.
Architecture overview
The hybrid architecture is designed around a simple principle: use the cloud where scale and governance matter, and use on-prem DGX where deterministic GPU performance is essential. The result is a unified ML platform where data engineering, orchestration, identity, and experiment management live in Azure, while deep learning workloads run on enterprise-owned GPU hardware.
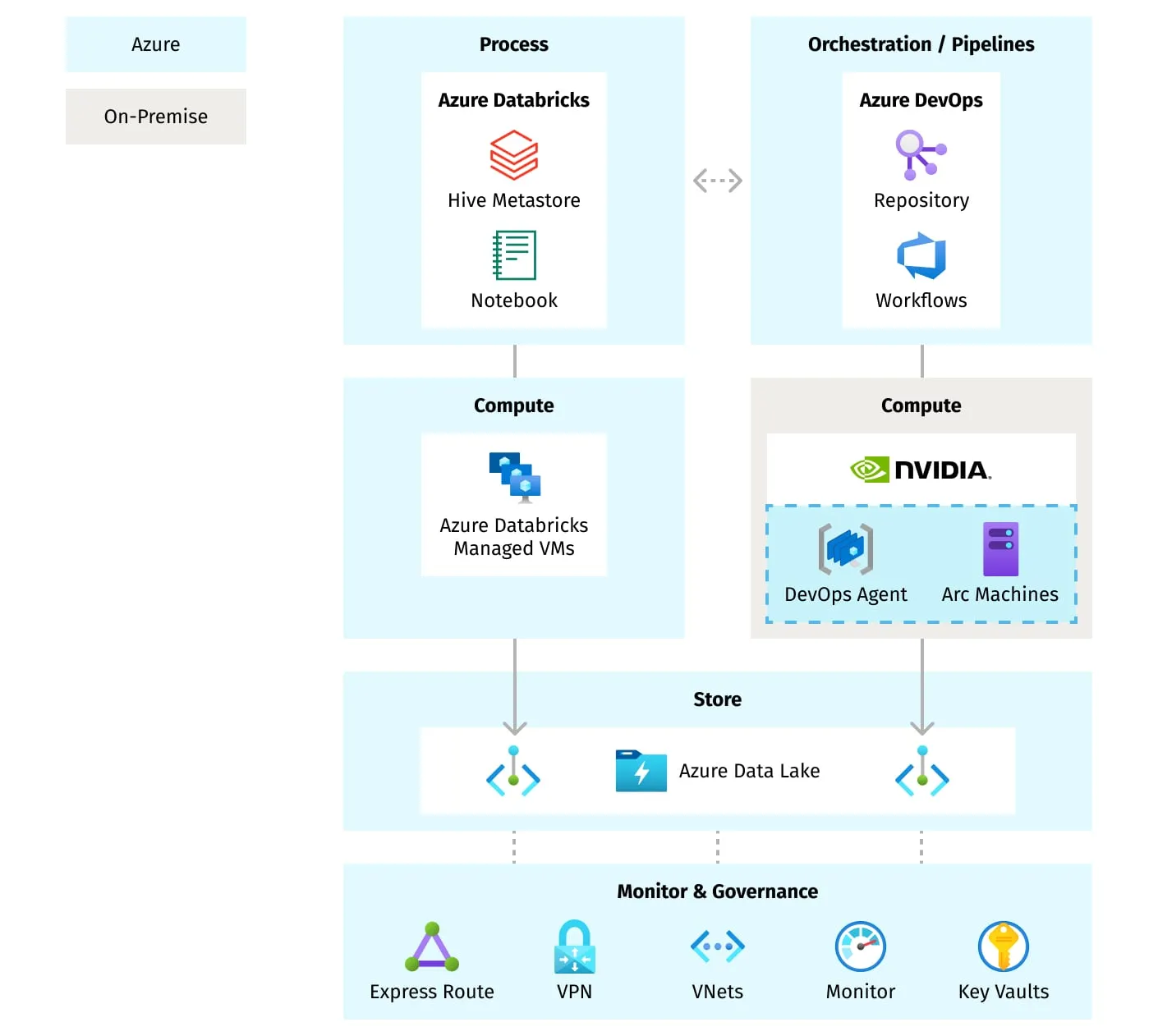
At a high level, the system is defined by four architectural pillars:
1. Unified data backbone
Azure Data Lake (ABFS) acts as the central storage fabric connecting cloud and on-prem systems. All raw, curated, and training-ready datasets live in the same lake, ensuring every component interacts with a consistent, versioned data layer.
Key properties:
- Unified schema enforced via Delta Lake
- Full RBAC (Role-Based Access Control) compliance through Azure AD
- Private network isolation with VPN + Private Link
- High-throughput parallel reads from DGX
2. Split-responsibility compute model
Cloud compute, Azure Databricks, handles the scalable, elastic portion of the pipeline: ETL, feature engineering, data normalization, and metadata management.
Key properties:
- Unified dataset catalog via Hive Metastore
- Scalable Spark execution
- Integration with Azure DevOps API
On-prem compute, NVIDIA DGX A100, provides predictable, high-performance GPU training without the volatility of cloud GPU costs.
Key properties:
- ARC integration for authentication, inventory, and policy enforcement
- Self-hosted Azure DevOps agent for automated pipeline execution
3. Cloud-orchestrated hybrid workflows
Azure DevOps serves as the orchestration plane, coordinating ETL, training, evaluation, and registration steps across both environments. From the user’s perspective, the pipeline behaves as one continuous workflow regardless of where each task executes.
Key properties:
- DAG-like orchestration of ETL → training → post-processing
- Containerized training execution on DGX
- Secure configuration delivery through Key Vault
- Unified logging and diagnostics via Azure Monitor / Log Analytics
4. Centralized governance and identity
Azure ARC brings the DGX machines under Azure’s governance umbrella. This makes hybrid execution feel cloud-native, with unified identity, policy enforcement, monitoring, and inventory management.
Key properties:
- DGX nodes as ARC-enabled servers
- Applied Azure Policy configurations
- Enforced RBAC with Azure AD
- Inventory visibility in Azure Portal
Together, these elements define the architecture at the conceptual level: cloud for data and governance; on-prem for GPU-powered training; and DevOps as the glue that keeps the pipeline coherent, secure, and repeatable.
Practical implementation choices
While hybrid machine learning architectures often involve many moving parts, the success of this implementation came down to a few key technology choices. The goal was not to reinvent the stack but to ensure seamless integration, traceability, and performance across Azure and on-prem environments. This section details how the hybrid system was built and the specific decisions that ensured reliability, security, and performance.
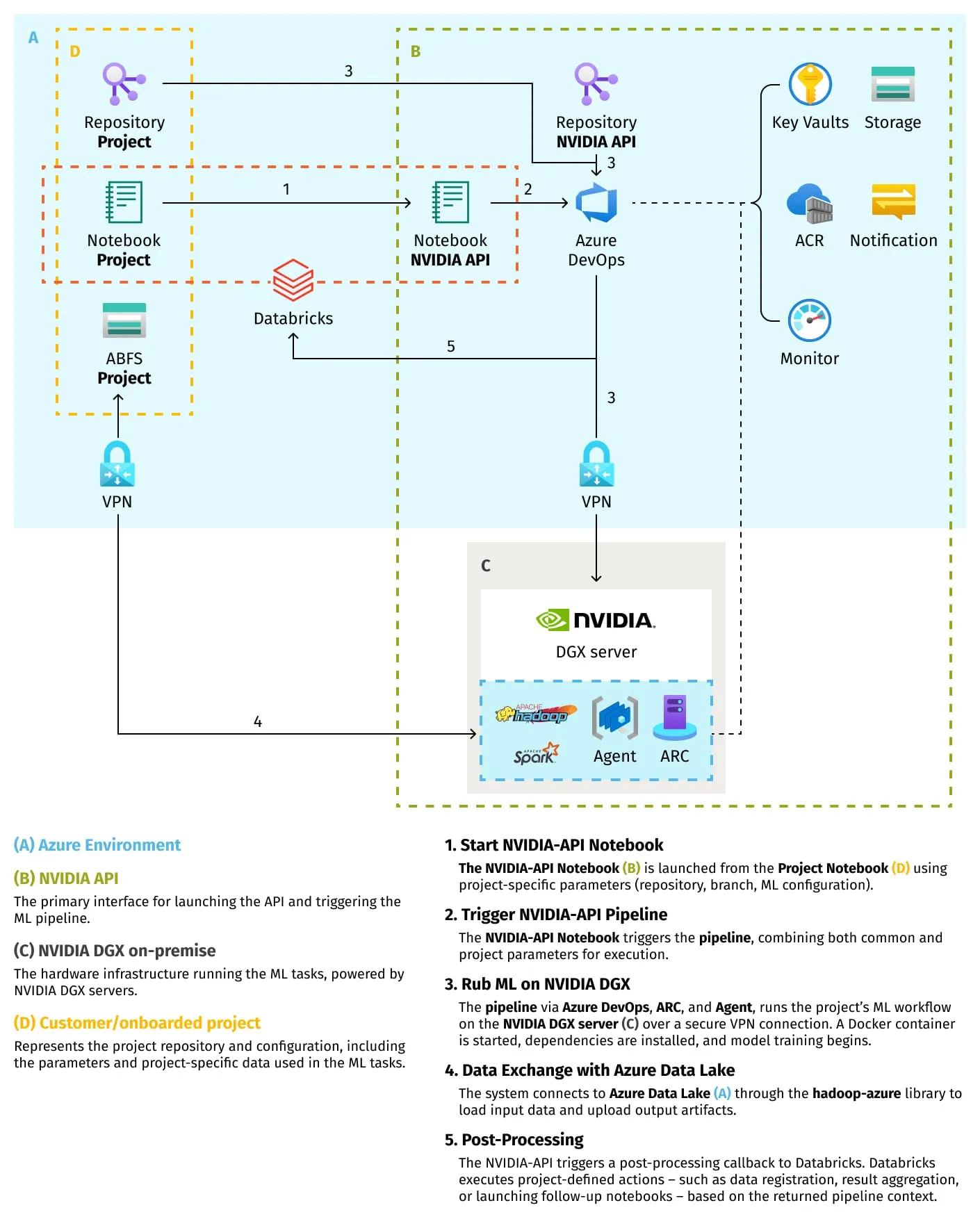
Data access layer
The hybrid platform required a data layer that could support both cloud-scale ETL and high-throughput on-prem GPU training. To achieve this, the team adopted a combined approach using Hadoop-Azure, Blobfuse2, and OAuth2-based Managed Identity authentication.
Hadoop-Azure (ABFS Connector)
Hadoop-Azure was selected as the core ABFS connector because it provides:
- High throughput for large-scale reads
- Native integration with Spark-based workflows
- Compatibility with Delta Lake formats
- Sufficient elasticity for Python and PyTorch data loading
- Extended Managed Identity support for Azure ARC
Blobfuse2 (POSIX Filesystem Access)
Blobfuse2 complements Hadoop-Azure by providing:
- POSIX semantics required for PyTorch DataLoaders
- Transparent behavior for ML frameworks
- Compatibility with potential Ray workloads
- A consistent filesystem abstraction over ABFS
Blobfuse2 enables GPU workloads to operate without modifying data access code or breaking training pipelines.
OAuth2 + Managed Identity
All authentication flows use OAuth2 combined with Managed Identity, providing:
- Complete removal of static secrets
- Alignment with Azure governance and compliance policies
- Unified identity model across cloud and ARC-enabled DGX nodes
This created a secure and fully governed authentication pathway for both cloud and on-prem resources.
Orchestration & automation
Azure DevOps provides the end-to-end orchestration layer for the hybrid pipeline, coordinating Databricks ETL, DGX training, and downstream post-processing within a single automated workflow.
The implementation uses a two-tier structure: NVIDIA-API and Customer ML layers.
NVIDIA-API layer
A shared execution layer that:
- Launches DGX training workloads
- Retrieves customer repositories at runtime
- Injects secure configuration via Key Vault
- Initializes the environment and executes containers
- Integrates logging, monitoring, and storage
This layer abstracts DGX execution into a reusable service for all ML teams.
Customer ML layer
Project repositories contain model code and ETL logic, relying on the NVIDIA-API pipelines for hybrid execution and benefiting from consistent operational and security standards.
Operational outcomes:
- Secretless configuration delivery
- Low-latency DGX execution via self-hosted agents
- Unified observability through Azure Monitor and Log Analytics
- Consistent orchestration from data preparation to model registration
Azure DevOps establishes a cohesive automation backbone that unifies cloud and on-prem workloads under one controlled execution model.
Governance and compliance layer
Azure ARC brings Azure-native governance to on-prem DGX nodes by registering them as ARC-enabled resources. This enables:
- Azure AD identity for unified authentication and audit trails
- Azure Policy enforcement for consistent security baselines
- Centralized visibility into configuration, health, and compliance via Azure Portal
Together with Azure DevOps, ARC provides a fully managed, compliant control plane that extends cloud-grade governance to the on-prem GPU environment.
Scalable data preparation
Azure Databricks functions as the platform’s large-scale data preparation engine, executing all ETL and feature engineering before data reaches the on-prem DGX. For forecasting workloads, Databricks processes multi-year global sales data to generate time-series features too large to prepare locally.
This design is driven by three capabilities:
- PySpark scalability: efficient parallel processing across auto-scaling clusters.
- Delta Lake consistency: strict schema enforcement on ABFS to ensure reliable downstream training.
- Hive Metastore catalog: a unified metadata layer so DGX reads the same curated tables Databricks writes.
Databricks outputs become the authoritative training datasets consumed directly by DGX workloads.
Experiment tracking
Azure-hosted MLflow, integrated with Databricks, serves as a single source of truth for experiment tracking, enabling seamless auditing and model comparison across environments, including on-prem DGX systems.
Capabilities:
- Centralized tracking: unified view of all experiments.
- Cross-environment support: DGX on-prem and Databricks integration.
- Secure config injection: MLFLOW_TRACKING_URI provided via Azure DevOps pipeline.
- Standardized logging: metrics and models logged consistently with MLflow API.
- Real-time visibility: immediate updates in Databricks UI.
The outcome is efficient, transparent experiment tracking with consistent auditability and seamless model comparison across platforms.
NVIDIA DGX training execution
The NVIDIA DGX A100 serves as the dedicated compute engine for training complex deep learning models in time-series forecasting. On-prem deployment provides predictable costs and supports large-batch, state-of-the-art neural network training.
Capabilities / Features:
- Cost predictability: on-prem DGX avoids unpredictable cloud OpEx (operational expenditures) from intensive experimentation and training.
- High-performance training: supports large batch sizes and advanced model architectures.
- Automated workflow: Azure DevOps pipeline triggers containerized training jobs.
- Data access optimization: HOST_NVIDIA=true variable signals on-prem execution for proper data handling and performance tuning.
The outcome is efficient, scalable, and cost-controlled AI model training with high-performance capabilities and automated workflows.
Risks and mitigations
Hybrid architectures combine cloud and on-premises systems, offering power and flexibility but introducing unique challenges. Proactive strategies are essential to ensure smooth, reliable operations.
Network latency and data transfer
Physical distance between DGX on-prem and Azure ABFS can create data bottlenecks, starving GPUs and reducing performance.
Mitigation:
- Dedicated connectivity: Use Azure ExpressRoute for low-latency, high-bandwidth transfer.
- Multi-layered caching:
- Hot cache: DGX internal SSDs for frequently accessed, low-latency datasets.
- Warm cache: On-prem NFS for larger, stable datasets pre-fetched from ABFS during off-peak hours. This acts as a long-term, persistent local mirror of your most important training data.
CUDA and driver mismatches
Differences in NVIDIA drivers, CUDA, or Python libraries across environments can cause runtime failures.
Mitigation:
- Containerized environments: Package each training job with all dependencies into Docker images for consistent, reproducible execution. This image is version-controlled and deployed to the DGX, guaranteeing a consistent, reproducible environment every time.
- Compatibility matrix: Maintain version-controlled records of validated NVIDIA drivers, CUDA versions, and libraries via Azure DevOps. This provides a clear, auditable record of the supported environments and helps prevent “it works on my machine” issues.
ML job orchestration and GPU resource contention
DGX is finite; simultaneous jobs may overwhelm resources, causing delays or failures.
Mitigation:
- Job queuing system: The NVIDIA-API orchestrates training requests, scheduling execution based on defined policies (FIFO, priority). This ensures the DGX server’s resources are utilized efficiently and prevents any single project from monopolizing the hardware.
- Status monitoring: Event-driven notifications via Azure Event Hub and Logic Apps provide real-time updates on job submission, execution, and completion. This allows stakeholders to receive automated email notifications with pipeline links and status updates, reducing uncertainty and improving the end-user experience.
Benefits and scalability
Hybrid machine learning is increasingly seen as the future-proof design pattern for enterprise AI. This approach meets growing governance, compliance, and security requirements, allowing organizations to maintain control over sensitive workloads while leveraging cloud resources where appropriate.
Business value & cost control
On-prem DGX servers handle GPU-intensive training workloads, significantly reducing unpredictable cloud operational expenditures. Cloud infrastructure remains strategically leveraged for data preparation, orchestration, and scaling during peak demand, ensuring cost predictability and efficient resource allocation.
Repeatable enterprise pattern
Once governance, IAM, and synchronization pipelines are configured, the implementation can be rolled out across multiple projects and business units. This creates a repeatable framework that accelerates the adoption of machine learning throughout the organization.
Practical scalability
- Incremental growth: Additional DGX nodes can be added with minimal reconfiguration, while Databricks ETL clusters can autoscale in response to data volume spikes.
- Distributed training: Containerized workloads enable multi-GPU or multi-node training without a full re-architecture, providing a clear path to scale as model complexity grows.
Industry applicability
- Regulated enterprises: Finance, healthcare, and retail organizations can process or train sensitive data on-premises while leveraging the cloud for large-scale feature engineering and collaboration.
- R&D teams: Maintain full control over GPU resources for experimentation while storing results centrally.
- Cost-sensitive units: Use a mix of local and cloud compute to manage budgets, avoid unexpected cloud bills, and retain agility.
Strategic outlook
This hybrid approach is future-ready. As infrastructure strategies evolve, workloads can flexibly shift between cloud and on-premises, preserving business continuity, optimizing costs, and protecting prior investments.
Practical implementation
This hybrid architecture has been successfully applied to several projects, significantly decreasing costs, particularly in a demand forecasting implementation.
The initial stages, including data loading, feature engineering, and feature selection, are orchestrated in the Azure Cloud using Azure Data Factory and Azure Databricks. However, the subsequent, resource-intensive steps—PyTorch model training and tuning for time-series data, which demand substantial GPU, CPU, or memory load—are performed on NVIDIA DGX, limiting their cost to electricity consumption only.
During the Proof of Concept (POC) stage, this setup was instrumental. It allowed the team to train, tune, and test numerous heavy models across multiple experiments without the fear of completely depleting the budget. This freedom enabled the team to explore all possible hypotheses, which ultimately led to the confident selection of the best model set.
In the production environment, this architecture continues to deliver significant savings on cloud compute costs. This is not limited to inference but also extends to the automated monitoring component, where model drift detection, retraining, and finetuning operate autonomously based on requirements.
The sense of freedom and confidence fostered by this architecture is shared across the entire project team, from business users and product owners to engineers. This positively impacts creative relationships with stakeholders, making it easier to test and implement new business ideas.
Conclusion
The hybrid deep learning architectures unify the elasticity of the cloud with the determinism and cost efficiency of on-prem GPU infrastructure. By combining Azure Databricks for ETL, ABFS for unified storage, Azure DevOps for orchestration, Azure ARC for governance, and NVIDIA DGX for high-performance training, we created a production-ready platform that delivers predictable costs, enterprise-grade compliance, and scalable performance.
What began as a single use case for the demand forecasting project evolved into a scalable enterprise standard applicable to computer vision, NLP, and time-series models.
The collaboration between ML Engineering, DevOps, Cloud Architecture, Security, and Infrastructure teams created a platform that is not only technically robust, but operationally sustainable, and ready to grow with future AI initiatives.
You might also like








